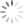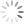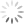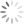


What is the python standard library?
Python Standard Libraries
are the collection of script modules that are accessible to a Python program to make the programming process simpler and to remove the need to rewrite commonly used commands again and again. They can be used by calling/importing them at the beginning of a python script.
It is important to become familiar with the Python Standard Library as so many problems can be solved quickly if you are familiar with the things that these libraries can do.
To have a look at the list of all available modules, you can type the following command in the python shell:
help('modules')And now you'll be able to check out below list: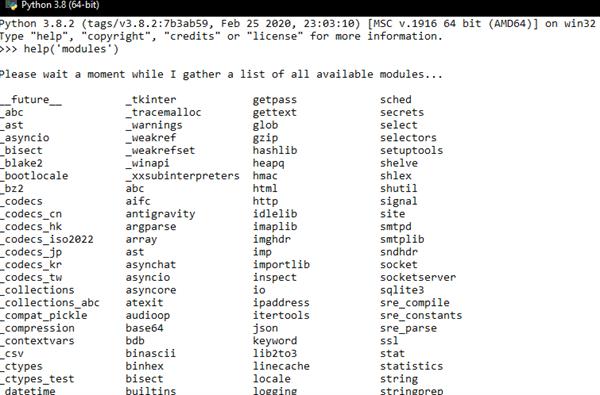
Note: This is not the complete list of the modules.
Common Standard Library Modules:
sys:
The sys module contains system-specific functionality. The sys module has a version_info tuple that gives us information about the version.
Example:
import sys
>>> sys.version_info
sys.version_info.major == 3
Output:

Date and Time:
The datetime module provides us with the objects which we can use to store information about date and time:
- datetime.date is used to create dates that are not associated with a time.
- datetime.time is used to have time independent of the date.
- datetime.datetime is used for objects which have both date and time.
- datetime.timedelta is used for objects to store differences in dates or datetime.
- datetime.timezone is used for objects that represent time zones as UTC.
We can have queries of these objects for a particular component like the year, month, hour or minute, perform arithmetic functions on them, extract printable string versions from them if we want to display them
Example:
import datetime
>>> now = datetime.datetime.today()
>>> print(now.year)
>>> print(now.hour)
>>> print(now.minute)
>>> print(now.weekday())
>>> print(now.strftime("%a, %d, %B, %Y"))
>>> long_ago = datetime.datetime(1993, 3, 14, 12,30, 58)
>>> print(long_ago) >>> print(long_ago < now)
>>> difference = now - long_ago
>>> print(type(difference))
>>> print(difference)
Output:
math:
The math module is a collection of mathematical functions. They are used on integers and on floats as well but are mostly used on floats and usually return floats too.
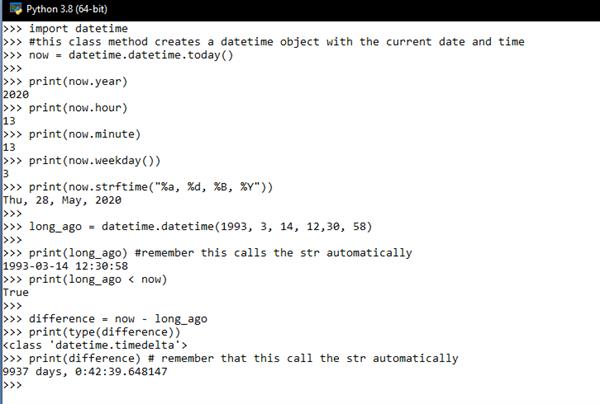
Example:
>>> import math
>>> #These are constant attributes, not functions
>>> math.pi
>>> math.e
>>> #round a float up or down
>>> math.ceil(3.3)
>>> math.floor(3.3)
>>> #natural algorithm
>>> math.log(5)
>>> #logrithm with base 10
>>> math.log(5,10)
>>> math.log10(5)
>>> # Square root
>>> math.sqrt(10)
>>> # trignometric function
>>> math.sin(math.pi/2)
>>> math.cos(0)
Output:
random:
This module is used to generate pseudo-random numbers (sequence of numbers) and also do some more things depending on randomness. The main function of this module generates a random float between 0 and 1 and most of the other functions are derived from it.
Example:
>>> import random
>>> # random float from 0 to 1 (excluding 1)
>>> random.random()
>>> pets = ['cat','dog','fish']
>>> # choose random element from the sequnece
>>> random.choice(pets)
>>> # shuffle a list (in place)
>>> random.shuffle(pets)
>>> print(pets)
>>> # random integer from 1 to 10 (inclusive)
>>> random.randint(1, 10)
Output:

re:
This module allows us to write regular expressions (mini-language for matching strings and can be used to find and replace text). The re module not only explains how to use the module but also contains a reference for the complete regular expression syntax which the python supports.
The re module provides us with various functions which allow us to use regular expressions in different ways –
- search searches for the regular expression inside a string.
- match matches a regular expression against the entire string.
- sub searches for the regular expression and replaces it with the provided replacement expression.
- findall searches for all matches of the regular expression within the string.
- split splits a string using any regular expression as a delimiter (sequence of one or more characters for specifying the boundary between separate, independent religions in plain text or other data streams).
- compile allows us to convert regular expression string to a pre-compiled regular expression object.
Example:
>>> import re
>>> #match and search are quite similar
>>> print(re.match("c.*t","cravat")) #this will match
<re.Match object; span=(0, 6), match='cravat'>
>>> print(re.match("c.*t","I have a cravat")) #this wont
>>> print(re.search("c.*t"," I have a cravat")) # this will
<re.Match object; span=(10, 16), match='cravat'>
>>> # we can use a static string as replacement as well
>>> print(re.sub("Lamb","Squirrel"," Mary had a little lamb"))
>>> print(re.sub("Lamb","Squirrel"," Mary had a little lamb"))
>>> # or we can capture groups, and substitute their contents back in.
>>> print(re.sub("(.*) (BITES) (.*)", r"\3 \2 \1"," Dogs bite men"))
>>> #count is a keyword parameter which we can use to limit replacement
>>> print(re.sub("a","b","aaaaaaaa"))
>>> print(re.sub("a","b","aaaaaaaa",count=1))
>>> #here's a closer look at match object.
>>> ny_match = re.match("(.*) (BITES) (.*)","DOG BITES MAN")
>>> print(ny_match.groups())
>>> print(ny_match.group(1))
>>> #we can name groups.
>>> ny_match = re.match("(?P<subject>.*) (?P<verb>BITES) (?P<objects>.*)","DOG BITES MAN")
>>> print(ny_match.group("subject")
Output:

urllib:
urllib module is used to handle and fetch URLs. urllib is a package that collects several modules for working with URLs like:
- urllib.request for opening and reading URLs.
import urllib.request
request_url = urllib.request.urlopen('https://www.google.com/')
print(request_url.read())
Output:
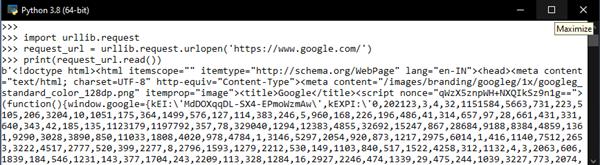
- urrlib.error contains the exceptions raised by urllib.request.
- urllib.parse for parsing URLs.
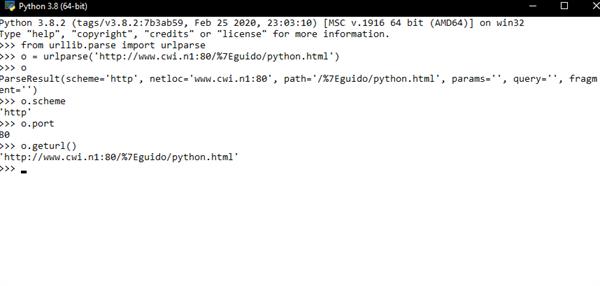
from urllib.parse import urlparse
>>> o = urlparse('http://www.cwi.n1:80/%7Eguido/python.html')
o.scheme
o.port
o.geturl()
Output:
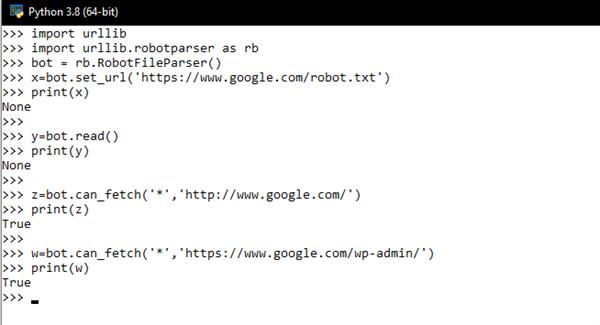
- urllib.robotparser for parsing robots.txt files. It tells whether or not a particular user can fetch a URL that publishes robot.txt files.
import urllib
import urllib.robotparser as rb
bot = rb.RobotFileParser()
x=bot.set_url('https://www.google.com/robot.txt')
print(x)
y=bot.read()
print(y)
z=bot.can_fetch('*','http://www.google.com/')
Output: