


What is Amazon Kinesis Data Firehose | AWS Kinesis Data Firehose
Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehose is the most straightforward approach to dependably stack spilling data into data lakes, data stores, and investigation instruments. It can catch, change, and burden gushing data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk, enabling near real-time analytics with existing business knowledge instruments and dashboards you're as of now utilizing today. It is a completely managed service that naturally scales to coordinate the throughput of your data and requires no progressing organization. It can likewise batch, compress, transform, and encrypt the data before stacking it, limiting the measure of capacity utilized at the goal and expanding security.

You can undoubtedly make a Firehose delivery stream from the AWS Management Console, configure it with a few clicks, and begin sending data to the stream from a huge number of data sources to be stacked persistently to AWS – all in only a couple of moments. You can likewise arrange your conveyance stream to naturally change over the approaching data to columnar configurations like Apache Parquet and Apache ORC, before the data is conveyed to Amazon S3, for cost-effective storage and analytics.
Benefits
Easy to use
Amazon Kinesis Data Firehose provides a simple way to capture, transform, and load streaming data with just a few clicks in the AWS Management Console. You can simply create a Firehose delivery stream, select the destinations, and you can start sending real-time data from hundreds of thousands of data sources simultaneously.
Integrated with AWS data lakes and data stores
Amazon Kinesis Data Firehose is integrated with Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service. From the AWS Management Console, you can point Kinesis Data Firehose to an Amazon S3 bucket, Amazon Redshift table, or Amazon Elasticsearch domain. You can then use your existing analytics applications and tools to analyze streaming data.
Serverless data transformation
Amazon Kinesis Data Firehose enables you to prepare your streaming data before it is loaded to data stores. With Kinesis Data Firehose, you can easily convert raw streaming data from your data sources into formats required by your destination data stores, without having to build your own data processing pipelines.
Near real-time
Amazon Kinesis Data Firehose captures and loads data in near real-time. It loads new data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk within 60 seconds after the data is sent to the service. As a result, you can access new data sooner and react to business and operational events faster.
No ongoing administration
Amazon Kinesis Data Firehose is a fully managed service that automatically provisions, manages, and scales compute memory, and network resources required to load your streaming data. Once set up, Kinesis Data Firehose loads data continuously as it arrives.
Features
Easy launch and configuration
You can launch Amazon Kinesis Data Firehose and create a delivery stream to load data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, or Splunk with just a few clicks in the AWS Management Console. You can send data to the delivery stream by calling the Firehose API, or running the Linux agent we provide on the data source. Kinesis Data Firehose then continuously loads the data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk.
Load new data in near real-time
You can indicate a batch size or bunch stretch to control how rapidly data is transferred to goals. For instance, you can set the batch interval to 60 seconds on the off chance that you need to get new data inside 60 seconds of sending it to your conveyance stream. Moreover, you can indicate if data ought to be compacted. The service underpins normal pressure calculations including GZip and Snappy. Batching and compacting data before transferring empowers you to control how rapidly you get new data at the goals.
Elastic scaling to handle varying data throughput
Once launched, your delivery streams automatically scale up and down to handle gigabytes per second or more of input data rate, and maintain data latency at levels you specify for the stream. No intervention or maintenance is needed.
Support for built-in data format conversion
Columnar data formats like Apache Parquet and Apache ORC are optimized for cost-effective storage and analytics utilizing services, for example, Amazon Athena, Amazon Redshift Spectrum, Amazon EMR, and other Hadoop based devices. Amazon Kinesis Data Firehose can change over the configuration of approaching data from JSON to Parquet or ORC formats before putting away the data in Amazon S3, so you can save stockpiling and analytics costs.
Integrated data transformations
You can configure Amazon Kinesis Data Firehose to set up your spilling data before it is stacked to data stores. Essentially select an AWS Lambda work from the Amazon Kinesis Data Firehose conveyance stream arrangement tab in the AWS Management console. Amazon Kinesis Data Firehose will consequently apply that capacity to each information data record and burden the changed data to goals. Amazon Kinesis Data Firehose gives pre-built Lambda blueprints to changing over regular data sources like Apache logs and framework logs to JSON and CSV formats. You can utilize these pre-manufactured plans with no change, or redo them further, or compose your own custom capacities. You can likewise arrange Amazon Kinesis Data Firehose to consequently retry failed jobs and back up the raw streaming data.
Support for multiple data destinations
Amazon Kinesis Data Firehose currently supports Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk as destinations. You can specify the destination Amazon S3 bucket, the Amazon Redshift table, the Amazon Elasticsearch domain, or the Splunk cluster into which data should be loaded.
Optional automatic encryption
Amazon Kinesis Data Firehose provides you the option to have your data automatically encrypted after it is uploaded to the destination. As part of the delivery stream configuration, you can specify an AWS Key Management System (KMS) encryption key.
Metrics for monitoring performance
Amazon Kinesis Data Firehose exposes a few metrics through the console, just as Amazon CloudWatch, including volume of data submitted, volume of data destinations, time from source to goal, and transfer achievement rate. You can utilize these measurements to screen the soundness of delivery streams, take any necessary actions such as modifying destinations and guarantee that the service is loading it to destinations.
Pay-as-you-go pricing
With Amazon Kinesis Data Firehose, you pay only for the volume of data you transmit through the service. There are no minimum fees or upfront commitments. You don’t need staff to operate, scale, and maintain infrastructure or custom applications to capture and load streaming data.
How it Works
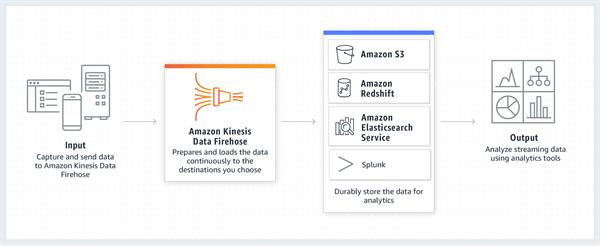
Data Flow
For Amazon S3 destinations, streaming data is delivered to your S3 bucket. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.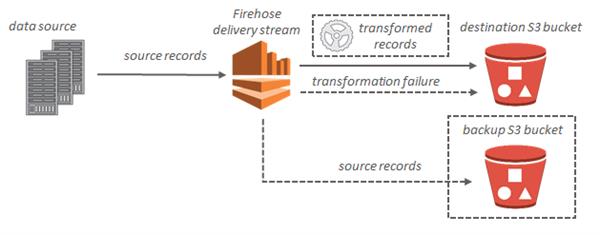
For Amazon Redshift destinations, streaming data is delivered to your S3 bucket first. Kinesis Data Firehose then issues an Amazon Redshift COPY command to load data from your S3 bucket to your Amazon Redshift cluster. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.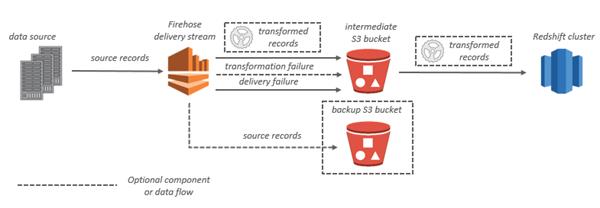
For Amazon ES destinations, streaming data is delivered to your Amazon ES cluster, and it can optionally be backed up to your S3 bucket concurrently.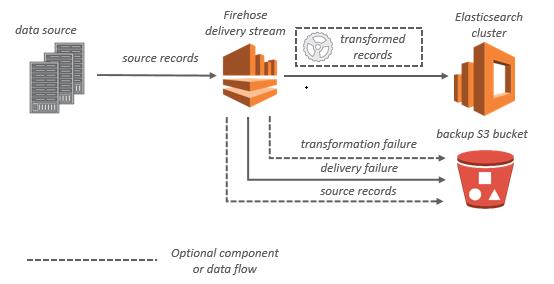
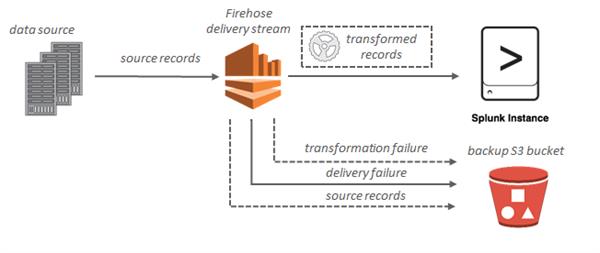
For Splunk destinations, streaming data is delivered to Splunk, and it can optionally be backed up to your S3 bucket concurrently.
Use Cases
Amazon Kinesis Data Firehose is the most straightforward approach to dependably load streaming data into data lakes, data stores, and analytics tools. It can catch, change, and burden gushing data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk, enabling near real-time analytics with existing business intelligence tools and dashboards you're as of now utilizing today. The following are instances of key use cases that the clients tackle using Amazon Kinesis Firehose.
IoT Analytics
With Amazon Kinesis Data Firehose, you can capture data continuously from connected devices such as consumer appliances, embedded sensors, and TV set-top boxes. Kinesis Data Firehose loads the data into Amazon S3 and Amazon Redshift, enabling you to provide your customers near-real-time access to metrics, insights, and dashboards.
Clickstream Analytics
You can use Amazon Kinesis Data Firehose to enable conveyance of real-time metrics on digital content, empowering creators, and marketers to associate with their clients in the best way. You can stream millions of small messages that are compressed, encrypted, and delivered to Amazon Elasticsearch Service and Amazon Redshift. From that point, you can aggregate, filter, and process the data, and refresh content performance dashboards in near real-time. For instance, Hearst Corporation fabricated a clickstream investigation stage utilizing Kinesis Data Firehose to transmit and process 30 terabytes of data every day from 300+ sites around the world. With this stage, Hearst can make the whole data stream—from site snaps to collected measurements—accessible to editors in minutes.
Log Analytics
Log data from your applications and servers running in the cloud and on-premises can assist you with checking your applications and investigate issues rapidly. For instance, you can distinguish application mistakes as they occur and recognize the main driver by gathering, observing, and dissecting log data. You can without much of a stretch introduce and design the Amazon Kinesis Agent on your servers to naturally watch application and server log records and send the data to Kinesis Data Firehose. Kinesis Data Firehose constantly streams the log data to Amazon Elasticsearch Service, so you can envision and break down the data with Kibana.
Security monitoring
Kinesis Data Firehose supports Splunk as a destination. This means that you can capture and send network traffic flow logs to Kinesis Data Firehose, which can transform, enrich, and load the data into Splunk. With this solution, you can monitor network security in real-time and alert when a potential threat arises.
