


What is AWS Data Lake?
AWS Data Lake
A data lake is a unified archive that permits you to store all your organized and unstructured data at any scale. You can store your data with no guarantees, without having to initially structure the data, and run various kinds of investigation—from dashboards and perceptions to enormous data handling, continuous examination, and AI to control better choices.
The need for data lake
Associations that effectively produce business esteem from their data, will beat their companions. An Aberdeen study saw associations who executed a Data Lake beating comparable organizations by 9% in natural income development. These pioneers had the option to do new kinds of examinations like AI over new sources like log documents, data from click-streams, web-based life, and web associated gadgets put away in the data lake. This helped them to recognize, and follow up on open doors for business development quicker by drawing in and holding clients, boosting profitability, proactively looking after gadgets, and settling on educated choices.
Data Lakes compared to Data Warehouses
Contingent upon the prerequisites, a normal association will require both a data warehouse and a data lake as they serve various needs, and use cases.
A data warehouse is a database upgraded to dissect social data originating from value-based frameworks and line of business applications. The data structure and diagram are characterized ahead of time to advance for quick SQL questions, where the outcomes are normally utilized for operational revealing and investigation. Data is cleaned, advanced, and changed so it can go about as the "single wellspring of truth" that clients can trust.
A data lake is extraordinary, in light of the fact that it stores social data from line of business applications, and non-social data from versatile applications, IoT gadgets, and web-based life. The structure of the data or outline isn't characterized when data is caught. This implies you can store the entirety of your data without cautious structure or the need to comprehend what addresses you may require answers for later on. Various kinds of investigation on your data like SQL inquiries, huge data examination, full content hunt, continuous investigation, and AI can be utilized to reveal bits of knowledge.
As associations with data warehouses see the advantages of data lakes, they are developing their warehouse to incorporate data lakes, and empower differing question abilities, data science use-cases, and propelled capacities for finding new data models. Gartner names this development as the "Data Management Solution for Analytics" or "DMSA.

Fundamental Components
As associations are building Data Lakes and an Analytics stage, they have to consider various key abilities including:
Data development
Data Lakes permit you to import any measure of data that can come progressively. Data is gathered from various sources and moved into the data lake in its unique configuration. This procedure permits you to scale to data of any size while sparing time of characterizing data structures, patterns, and changes.
Safely store, and list data
Data Lakes permit you to store social data like operational databases and data from line of business applications, and non-social data like portable applications, IoT gadgets, and web-based social networking. They additionally enable you to comprehend what data is in the lake through slithering, classifying, and ordering of data. At last, data must be made sure about to guarantee your data resources are ensured.
Analytics
Data Lakes permit different jobs in your association like data researchers, data designers, and business experts to get to data with their decision of investigative devices and structures. This incorporates open source systems, for example, Apache Hadoop, Presto, and Apache Spark, and business contributions from data warehouse and business knowledge merchants. Data Lakes permit you to run an investigation without the need to move your data to a different examination framework.
ML
Data Lakes will permit associations to create various sorts of bits of knowledge remembering detailing for recorded data, and doing AI where models are worked to conjecture likely results, and recommend a scope of endorsed activities to accomplish the ideal outcome.
The value of Data
The estimation of a Data Lake
The capacity to bridle more data, from more sources, in less time, and enabling clients to work together and break down data in various manners prompts better, quicker dynamic. Models where Data Lakes have included worth include:
Improved client communications
A Data Lake can consolidate client data from a CRM stage with web-based life investigation, an advertising stage that incorporates purchasing history, and episode passes to engage the business to comprehend the most beneficial client partner, the reason for client stir, and the advancements or prizes that will build dependability.
Improve R&D development decisions
A data lake can help your R&D groups test their speculation, refine presumptions, and evaluate results, for example, picking the correct materials in your item configuration bringing about quicker execution, doing genomic research prompting progressively compelling medicine, or understanding the eagerness of clients to pay for various characteristics.
Increment operational efficiencies
The Internet of Things (IoT) acquaints more ways to gather data on forms like assembling, with ongoing data originating from web associated gadgets. A data lake makes it simple to store, and run an examination on machine-created IoT data to find approaches to decrease operational expenses and increment quality.
AWS Lake formation
AWS Lake Formation is assistance that makes it simple to set up a safe data lake in days. A data lake is a concentrated, curated, and made sure about the vault that stores every one of your data, both in its unique structure and arranged for examination. A data lake empowers you to separate data storehouses and join various sorts of examinations to pick up bits of knowledge and guide better business choices.
Be that as it may, setting up and overseeing data lakes today includes a ton of manual, convoluted, and tedious undertakings. This work incorporates stacking data from various sources, checking those data streams, setting up parcels, turning on encryption and overseeing keys, characterizing change occupations and observing their activity, re-sorting out data into a columnar arrangement, designing access control settings, deduplicating excess data, coordinating connected records, conceding access to data sets, and inspecting access after some time.
Making a data lake with Lake Formation is as straightforward as characterizing data sources and what data access and security approach you need to apply. Lake Formation at that point causes you to gather and list data from databases and article stockpiling, move the data into your new Amazon S3 data lake, clean and arrange your data utilizing AI calculations, and secure access to your touchy data. Your clients can get to an incorporated data inventory that portrays accessible data sets and their proper use. Your clients at that point influence these data sets with their decision of examination and AI administrations, similar to Amazon Redshift, Amazon Athena, and (in beta) Amazon EMR for Apache Spark. Lake Formation expands on the abilities accessible in AWS Glue.
Advantages
Construct data lakes rapidly
With Lake Formation, you can move, store, list, and clean your data quicker. You essentially point Lake Formation at your data sources, and Lake Formation creeps those sources and moves the data into your new Amazon S3 data lake. Lake Formation arranges data in S3 around much of the time utilized inquiry terms and into right-sized pieces to build productivity. Lake Formation likewise changes data into positions like Apache Parquet and ORC for quicker investigation. What's more, Lake Formation has worked in AI to deduplicate and discover coordinating records (two sections that allude to something very similar) to build data quality.
Streamline security the executives
You can utilize Lake Formation to midway characterize security, administration, and inspecting strategies in a single spot, as opposed to carrying out these responsibilities per administration, and afterward uphold those approaches for your clients over their examination applications. Your strategies are reliably executed, dispensing with the need to physically design them across security administrations like AWS Identity and Access Management and AWS Key Management Service, stockpiling administrations like S3, and examination and AI administrations like Redshift, Athena, and (in beta) EMR for Apache Spark. This decreases the exertion in designing strategies across administrations and gives reliable requirements and consistency.
Offer self-support access to data
With Lake Formation you assemble a data index that depicts the various data sets that are accessible alongside which gatherings of clients approach each. This makes your clients progressively beneficial by helping them locate the correct data set to break down. By furnishing an index of your data with steady security implementation, Lake Formation makes it simpler for your investigators and data researchers to utilize their favored examination administration.
They can utilize EMR for Apache Spark (in beta), Redshift, or Athena on different data sets presently housed in a solitary data lake. Clients can likewise consolidate these administrations without moving data between storehouses.
How it functions
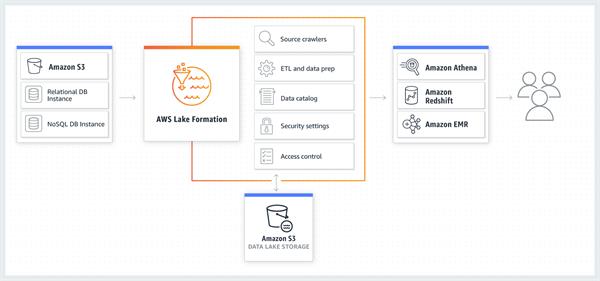
Lake Formation assists with building, secure, and deals with your data lake. To begin with, recognize existing data stores in S3 or social and NoSQL databases, and move the data into your data lake. At that point creep, index, and set up the data for examination. At that point give your clients secure self-administration access to the data through their decision of examination administrations. Different AWS administrations and outsider applications can likewise get to data through the administrations appeared. Lake Formation deals with the entirety of the errands in the orange box and is incorporated with the data stores and administrations appeared in the blue boxes.
Assemble data lakes rapidly
Import data from databases as of now in AWS
When you determine where your current databases are and give your entrance accreditations, Lake Formation peruses the data and its metadata (outline) to comprehend the substance of the data source. Lake Formation at that point imports the data to your new data lake and records the metadata in a focal list. With Lake Formation, you can import data from MySQL, Postgres, SQL Server, MariaDB, and Oracle databases running in Amazon RDS or facilitated in Amazon EC2. Both mass and gradual data stacking are upheld.
Import data from other outer sources
You can utilize Lake Formation to move data from on-premises databases by associating with Java Database Connectivity (JDBC.) Identify your objective sources and give get to accreditations in the reassure, and Lake Formation peruses and stacks your data into the data lake. To import data from databases other than the ones recorded above, you can make custom ETL employments with AWS Glue.
Import data from different AWS administrations
Utilizing Lake Formation, you can likewise pull in semi-organized and unstructured data from other S3 data sources. You can distinguish existing Amazon S3 basins containing data to duplicate into your data lake. When you indicate the S3 way to enroll your data sources and approve get to, Lake Formation peruses the data and its composition. Lake Formation can gather and compose data sets, similar to logs from AWS CloudTrail, AWS CloudFront, Detailed Billing Reports, and AWS Elastic Load Balancing. You can likewise stack your data into the data lake with Amazon Kinesis or Amazon DynamoDB utilizing custom occupations.
List and mark your data
Lake Formation creeps and peruses your data sources to separate specialized metadata (like construction definitions) and makes an accessible list to depict this data for clients, so they can find accessible data sets. You can likewise include your own custom marks, at the table-and segment level, to your data to characterize properties, similar to "touchy data" and "European deals data." Lake Formation gives a book based hunt over this metadata, so your clients can rapidly discover the data they have to break down.
Change data
Lake Formation can perform changes on your data, for example, reworking different date designs for consistency, to guarantee that the data is put away in an investigation agreeable manner. Lake Formation makes change layouts and calendars occupations to set up your data for investigation. Your data is changed with AWS Glue and written in columnar arrangements, for example, Parquet and ORC, for better execution. Fewer data should be perused for examination when data is composed into sections as opposed to checking whole lines. You can make custom change employments with AWS Glue and Apache Spark to suit your particular prerequisites.
Clean and deduplicate data
Lake Formation helps clean and set up your data for examination by giving a Machine Learning Transform called FindMatches for deduplication and finding coordinating records. For instance, use Lake Formation's FindMatches to discover copy records in your database of cafés, for example, when one record records "Joe's Pizza" at "121 Main St." and another shows a "Joseph's Pizzeria" at "121 Main." You don't have to know anything about AI to do this. FindMatches will simply solicit you to name establishes from precedents as either "coordinating" or "not coordinating." The framework will at that point gain proficiency with your rules for calling a couple of records a "coordinate" and will fabricate an ML Transform that you can use to discover copy records inside a database or coordinating records across two databases.
Enhance segments
Lake Formation likewise streamlines the dividing of data in S3 to improve execution and lessen costs. Crude data that is stacked might be in segments that are excessively little (requiring additional peruses) or excessively enormous (perusing a larger number of data than required.) With Lake Formation, your data is sorted out by size, timeframe, or potentially important keys. This empowers both quick outputs and equal, dispersed peruses for the most normally utilized inquiries.
Disentangle security the executives
Uphold encryption
Lake Formation uses the encryption capacities of S3 for data in your data lake. This methodology furnishes programmed server-side encryption with keys oversaw by the AWS Key Management Service (KMS). S3 encodes data in travel while imitating across districts, and lets you utilize separate records for source and goal locales to ensure against malevolent insider erasures. These encryption capacities give a safe establishment to all data in your data lake.
Characterize and oversee get to controls
Lake Formation gives focal access controls to data in your data lake. You can characterize security strategy based guidelines for your clients and applications by the job in Lake Formation, and reconciliation with AWS IAM validates those clients and jobs. When the standards are characterized, Lake Formation upholds your entrance controls at table-and section level granularity for clients of Amazon Redshift Spectrum and Amazon Athena. AWS Glue gets to is upheld at the table-level and is commonly for heads as it were. EMR coordination (in beta) bolsters approving Active Directory, Okta, and Auth0 clients for EMR Notebooks and Zeppelin scratchpad associated with EMR bunches.
Actualize review logging
Lake Formation gives exhaustive review logs CloudTrail to screen access and show consistency with midway characterized approaches. You can review data get to history across investigation and AI benefits that read the data in your data lake through Lake Formation. This lets you see which clients or jobs have endeavored to get to what data, with which administrations, and when. You can get to review signs similarly you get to some other CloudTrail logs utilizing the CloudTrail APIs and Console.
Offer self-assistance access to data
Mark your data with business metadata
Lake Formation gives you the capacity to assign data proprietors, for example, data stewards and specialty units, by including a field in table properties as custom characteristics. Your proprietors can enlarge the specialized metadata with business metadata that further characterizes fitting uses for the data. You can indicate proper use cases and mark the affectability of your data for authorization by utilizing Lake Formation security and access controls.
Empower self-administration to get to
Lake Formation encourages mentioning and distributing access to datasets to give your clients self-administration access to the data lake for an assortment of examination use cases. You can indicate, award, and deny authorizations on tables characterized in the focal data list. A similar data index is accessible for various records, gatherings, and administrations.
Find significant data for investigation
With Lake Formation, your clients appreciate on the web, text-based hunt, and sifting of data sets recorded in the focal data index. They can scan for significant data by name, substance, affectability, or other some other custom marks you have characterized.
Join examination approaches for additional bits of knowledge
With Lake Formation, you can enable your examination clients to legitimately inquiry datasets with Athena for SQL, Redshift for data warehousing, and (in beta) EMR for Apache Spark-based huge data preparing and AI (for EMR Notebooks and Zeppelin scratchpad). When you guide these administrations toward Lake Formation, the data sets accessible have appeared in the index and access controls are upheld reliably, permitting your clients to promptly consolidate examination approaches on similar data.
