


What is AWS Kendra | Amazon Kendra
AWS Kendra
Amazon Kendra is an enterprise search service that empowers your users to instinctively look through unstructured data utilizing natural language. It returns specific responses to questions, giving users an encounter that is near cooperating with a human master. It is exceptionally accessible and adaptable, firmly coordinated with different AWS services, and offers enterprise-grade security.
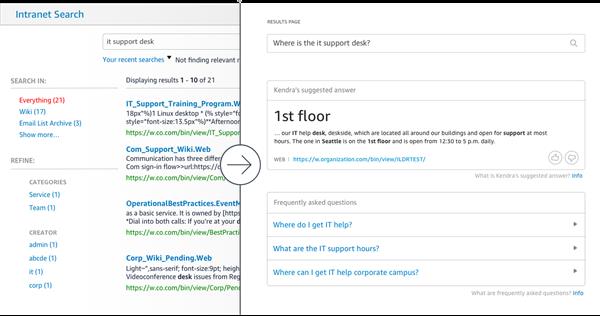
Amazon Kendra users can ask the following types of inquiries, or questions:
- Factoid questions — Simple who, what, when, or where questions, for example, Who is Amazon's CEO? or then again What is the tallness of the Space Needle?. Factoid questions have actuality based answers that can be returned as a solitary word or expression. The exact answer, be that as it may, must be explicitly expressed in the ingested text content.
- Descriptive questions — Questions whose answer could be a sentence, passage, or a whole document. For instance, How would I interface my Echo Plus to my network? or on the other hand, How would I get tax reductions for lower-income families?.
- Keyword searches —For questions where the expectation and scope aren't clear, for instance, vacation policy or health benefits, Amazon Kendra utilizes its deep learning models to return relevant documents.
Editions
Developer Edition
The Amazon Kendra Developer Edition provides all of the features of Amazon Kendra at a lower cost. It includes a free tier that provides 750 hours of use. The Developer Edition is ideal to explore how Amazon Kendra indexes your documents, to try out features, and to develop applications that use Amazon Kendra.
The developer edition provides the following:
- Up to 5 indexes with up to 5 data sources each
- 10,000 documents or 3 Gb of extracted text
- 4,000 queries per day
- Runs in 1 availability zone (AZ)
You should not use the Developer Edition for a production application. The Developer Edition doesn't provide any guarantees of latency or availability.
Enterprise Edition
Use Amazon Kendra Enterprise Edition when you want to index your entire enterprise document library or for when your application is ready for use in a production environment. The enterprise edition provides the following. You can increase this quota using the Service Quotas console.
- Up to 5 indexes with up to 50 data sources each.
- 500,000 documents or 150 Gb of extracted text
- 40,000 queries per day.
- Runs in 3 availability zones (AZ)
Benefits
Accuracy
Unlike traditional search services that utilize keyword searches where results depend on basic keyword matching and ranking, Amazon Kendra endeavors to comprehend the content, the user context, and the question. Amazon Kendra looks over your data and goes beyond conventional search to restore the most relevant word, snippet, or document for your query. Amazon Kendra utilizes AI to improve search results over time.
Simplicity
Amazon Kendra provides a console and API for managing the documents that you like to search about. You can use a simple search API to integrate Amazon Kendra into your client applications, such as websites or mobile applications.
Connectivity
Amazon Kendra can connect to third-party data sources to provide search across documents managed in different environments.
Features
Natural language & keyword support
Amazon Kendra's ability to comprehend normal language questions is at the core of its search engine, so end clients have the ability to scan for general keywords like "health benefits" or increasingly explicit natural language questions like "how long is maternity leave?". Kendra will return specific answers like "14 weeks", or for the broader searches, Kendra will restore the most relevant section and related archives. Natural language empowers you to find increasingly explicit solutions from anywhere in your data.
Reading comprehension & FAQ matching
Amazon Kendra can extract specific answers from unstructured data. No pre-training is required, you just point Kendra at your content and Kendra will give explicit responses to common language questions like "how do I configure my VPN?" where the appropriate response is consequently removed from the most pertinent record. You can likewise transfer a rundown of FAQs to Kendra to give straightforward replies answers to regular inquiries your end clients are asking. Kendra will locate the closest question to the search query and return the corresponding answer.
Document ranking
To complement the extracted answers, Amazon Kendra uses a deep learning-based semantic search model to return a ranked list of relevant documents. This provides the end-user a more exhaustive list of content to explore should they need more information.
Connectors
Utilize Kendra's connectors for famous sources like S3, SharePoint, Salesforce, Servicenow, RDS databases, One Drive, and a lot more coming later this year. Utilizing connectors is speedy and simple, you simply add data sources to your Kendra list and select the connector type. Connectors will keep up the document access rights and can be planned to naturally synchronize your index with your data source, so you're in every case safely looking through the most up to date content. For other data source types, Kendra offers an API that permits you to construct your own connector and upload documents from your ETL job or back-end application. Since every data source may contain distinctive record types, Kendra underpins unstructured and semi-organized data in HTML, MS Office Word and PowerPoint, PDF, and Text formats.
Relevance tuning
You can boost certain fields in your index to assign more significance to specific responses. Amazon Kendra permits you to tune for specific data sources or document freshness. For instance, while scanning for "When is re:invent?" you can boost the significance of document freshness with the goal that the 2019 dates are the proposed answer. Or on the other hand, you could support an increasingly trustworthy data source in an index of research reports. Kendra additionally bolsters boosting documents that depend upon on a vote or view count, which is basic in forums and other support type information bases. Consolidating these boosting features would, for instance, boost documents that are not only viewed more often but that is also more recent, like trending news or updates.
Domain optimization
Kendra uses deep learning models to understand natural language queries and document content and structures for a wide range of internal use cases like HR, operations, support, and R&D. Kendra is also optimized to understand the complex language from domains like IT, financial services, insurance, pharmaceuticals, industrial manufacturing, oil and gas, legal, media and entertainment, travel and hospitality, health, HR, news, telecommunications, mining, food and beverage, and automotive. For example, a user searching for HR answers could enter the "deadline for filing HSA form" and Kendra would also search for "deadline for filing health savings account form" for broader coverage to get the most accurate answer. You can further improve domain expertise by providing your own synonym lists (coming soon). You just upload a file with your specific terminology and Kendra will use these synonyms to enrich user searches.
How it Works
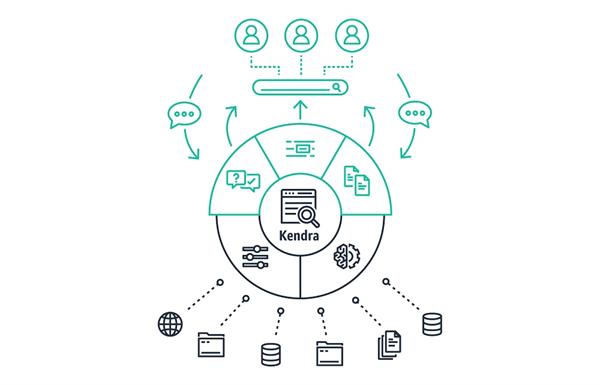
End-users interact with Kendra by searching for answers within an application, website, search bar, or chatbot interface. The upper half of the Kendra circle in green represents the three main response types from Kendra, including matching to FAQs, reading comprehension to extract suggested answers, and document ranking. The lower part of the circle includes under-the-hood features of Kendra, including relevance tuning and incremental learning. Lastly, you can see the content that can be indexed into Kendra, using built-in connectors for popular data sources.
Customers
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
