


What is AWS Data Pipeline
AWS Data Pipeline
AWS Data Pipeline is a web service that you can use to automate the development and transformation of data. With AWS Data Pipeline, you can characterize data-driven workflow, so that the tasks can be reliant on the successful completion of past undertakings. You characterize the parameters of your data transformations and AWS Data Pipeline implements the logic that you've set up.

The following components of AWS Data Pipeline work together to manage your data:
- A pipeline definition indicates the business logic of your data management.
- Pipeline schedules and runs tasks by generating Amazon EC2 examples to perform the characterized work activities. You upload your pipeline definition to the pipeline, and afterward activates the pipeline. You can alter the pipeline definition for a running pipeline and activate the pipeline again for it to take effect. You can deactivate the pipeline, modify a data source, and afterward activate the pipeline again. At the point when you are done with your pipeline, you can delete it.
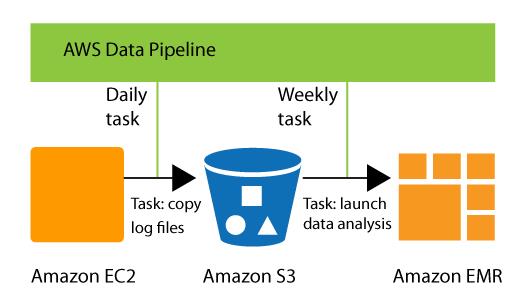
- Task Runner polls for tasks and afterward perform those tasks. For instance, Task Runner could copy log files to Amazon S3 and launch Amazon EMR clusters. Task Runner is installed and runs consequently on resources made by your pipeline definitions. You can compose a custom task runner application, or you can utilize the Task Runner application that is provided by the AWS Data Pipeline.
For instance, you can utilize AWS Data Pipeline to archive your web server's logs to Amazon Simple Storage Service (Amazon S3) every day and afterward run a weekly Amazon EMR (Amazon EMR) cluster over those logs to create traffic reports. AWS Data Pipeline plans the everyday tasks to copy data and week by week tasks to launch the Amazon EMR cluster. AWS Data Pipeline also guarantees that Amazon EMR trusts that the last day's data will be transferred to Amazon S3 before it starts its analysis, regardless of whether there is an unanticipated delay in uploading the logs.
Benefits
Reliable

AWS Data Pipeline is based on a distributed, exceptionally accessible infrastructure intended for fault-tolerant execution of your activities. On the off chance that failures occur in your activity logic or data sources, AWS Data Pipeline consequently retries the activity. If the failure persists, AWS Data Pipeline sends you failure notifications by means of Amazon Simple Notification Service (Amazon SNS). You can configure your notifications for successful runs, delays in planned activities, or failures.
Easy to Use
Creating a pipeline is speedy and simple via their simplified drag-and-drop console. Common preconditions are incorporated into the service, so you don't have to compose any additional logic to utilize them. For instance, you can check for the presence of an Amazon S3 file by simply giving the name of the Amazon S3 bucket and the path of the file that you need to check for, and AWS Data Pipeline does the rest. In addition to its simple visual pipeline creator, AWS Data Pipeline gives a library of pipeline templates. These templates make it easy to make pipelines for various number use cases, like regularly processing your log files, archiving data to Amazon S3, or running periodic SQL queries.
Flexible

AWS Data Pipeline allows you to exploit an assortment of features, like scheduling, dependency tracking, and error handling. You can use activities and preconditions that AWS gives or provides and/or write your own custom ones. This implies you can arrange an AWS Data Pipeline to take actions like run Amazon EMR jobs, execute SQL queries directly against databases, or execute custom applications running on Amazon EC2 or in your own datacenter. This allows you to make incredible custom pipelines to analyze and process your data without managing the complexities of reliably scheduling and executing your application logic.
Scalable
AWS Data Pipeline makes it equally easy to dispatch work to one machine or many, in serial or parallel. With AWS Data Pipeline’s flexible design, processing a million files is as easy as processing a single file.
Low Cost
AWS Data Pipeline is inexpensive to use and is billed at a low monthly rate. You can try it for free under the AWS Free Usage.
Transparent
You have full control over the computational resources that execute your business logic, making it simple to enhance or debug your logic. Furthermore, full execution logs are automatically delivered to Amazon S3, giving you a persistent, detailed record of what has happened in your pipeline.
Accessing AWS Data Pipeline
You can create, access, and manage your pipelines using any of the following interfaces:
- AWS Management Console—Provides a web interface that you can use to access AWS Data Pipeline.
- AWS Command Line Interface (AWS CLI) — Provides commands for a wide set of AWS administrations, including AWS Data Pipeline, and is supported on Windows, macOS, and Linux. For more information about introducing the AWS CLI, see AWS Command Line Interface.
- AWS SDKs — Provides language-explicit APIs and deals with huge numbers of the connection details, like calculating signatures, handling request retries, and error handling.
- Query API—Provides low-level APIs that you call utilizing HTTPS requests. Utilizing the Query API is the most immediate approach to get to AWS Data Pipeline, however, it requires that your application handles low-level details like generating the hash to sign the request and error handling.
