


What is AWS Aurora?
Amazon Aurora
Amazon Aurora is a MySQL and PostgreSQL-good relational database worked for the cloud, that joins the exhibition and accessibility of customary endeavor databases with the straightforwardness and cost-viability of open source databases. Amazon Aurora is up to multiple times quicker than standard MySQL databases and multiple times quicker than standard PostgreSQL databases. It gives the security, accessibility, and dependability of business databases at 1/tenth the expense. Amazon Aurora is completely overseen by Amazon Relational Database Service (RDS), which robotizes tedious organization undertakings like equipment provisioning, database arrangement, fixing, and reinforcements.

Amazon Aurora includes a disseminated, deficient open-minded, self-mending stockpiling framework that auto-scales up to 64TB per database occasion. It conveys elite and accessibility with up to 15 low-dormancy read reproductions, point-in-time recuperation, persistent reinforcement to Amazon S3, and replication across three Availability Zones (AZs). Aurora is a piece of the oversaw database administration Amazon Relational Database Service (Amazon RDS). Amazon RDS is a web administration that makes it simpler to set up, work, and scale a relational database in the cloud.
The accompanying focuses delineate how Aurora identifies with the standard MySQL and PostgreSQL motors accessible in Amazon RDS:
You pick Aurora as a DB motor choice when setting up new database servers through Amazon RDS.
Aurora exploits the recognizable Amazon Relational Database Service (Amazon RDS) highlights for the board and organization. Aurora utilizes the Amazon RDS AWS Management Console interface, AWS CLI orders, and API activities to deal with routine database undertakings, for example, provisioning, fixing, reinforcement, recuperation, disappointment recognition, and fix.
Aurora the executives' tasks regularly include whole groups of database servers that are synchronized through replication, rather than singular database occurrences. The programmed bunching, replication, and capacity allotment make it straightforward and financially savvy to set up, work, and scale your biggest MySQL and PostgreSQL organizations.
You can bring information from Amazon RDS for MySQL and Amazon RDS for PostgreSQL into Aurora by making and reestablishing depictions, or by setting up single direction replication. You can utilize press button relocation devices to change over your current Amazon RDS for MySQL and Amazon RDS for PostgreSQL applications to Aurora.
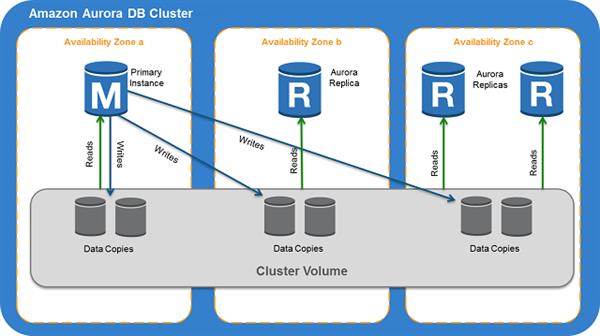
Amazon Aurora DB Clusters:
An Amazon Aurora DB group comprises of at least one DB occasions and a bunch volume that deals with the information for those DB cases. An Aurora group volume is a virtual database stockpiling volume that traverses different Availability Zones, with every Availability Zone having a duplicate of the DB bunch information. Two kinds of DB occasions make up an Aurora DB group:
Essential DB occasion
Supports read and write activities, and plays out the entirety of the information alterations to the bunch volume. Every Aurora DB group has one essential DB occurrence.
Aurora Replica
Connects to a similar stockpiling volume as the essential DB example and supports just read activities. Every Aurora DB group can have up to 15 Aurora Replicas notwithstanding the essential DB occasion. Keep up high accessibility by finding Aurora Replicas in discrete Availability Zones. Aurora consequently flops over to an Aurora Replica in the event that the essential DB occurrence gets inaccessible. You can determine the failover need for Aurora Replicas. Aurora Replicas can likewise offload read outstanding tasks at hand from the essential DB case.
For Aurora multi-ace bunches, all DB occasions have perused/compose capacity. For this situation, the differentiation between the essential case and Aurora Replica doesn't have any significant bearing. For talking about replication geography where the bunches can utilize either single-ace or multi-ace replication, we call this reader and writer DB occurrences.
Amazon Aurora Connection Management
Amazon Aurora ordinarily includes a group of DB occurrences rather than a solitary case. Every association is dealt with by a particular DB case. At the point when you associate with an Aurora group, the hostname, and port that you indicate point to a halfway handler called an endpoint. Aurora utilizes the endpoint instrument to digest these associations. In this manner, you don't need to hardcode all the hostnames or compose your own rationale for load-adjusting and rerouting associations when some DB occurrences aren't accessible.
For certain Aurora undertakings, various examples or gatherings of occasions perform various jobs. For instance, the essential case handles all information definition language (DDL) and information control language (DML) explanations. Up to 15 Aurora Replicas handle read-just inquiry traffic.
Utilizing endpoints, you can plan every association with the fitting example or gathering of occasions dependent on your utilization case. For instance, to perform DDL explanations you can associate with whichever example is the essential occurrence.
Types of Aurora Endpoints
An endpoint is spoken to as an Aurora-explicit URL that contains a host address and a port. The accompanying sorts of endpoints are accessible from an Aurora DB group.
Cluster endpoint
A group endpoint (or author endpoint) for an Aurora DB bunch associates with the current essential DB occasion for that DB bunch. This endpoint is the one in particular that can perform composing tasks, for example, DDL proclamations. Along these lines, the group endpoint is the one that you associate with when you previously set up a bunch or when your group just contains a solitary DB case. The following example illustrates a cluster endpoint for an Aurora MySQL DB cluster.
mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com:3306
Reader endpoint
A reader endpoint for an Aurora DB bunch gives load-adjusting backing to peruse just associations with the DB group. Utilize the reader endpoint for read activities, for example, questions. By preparing those announcements on the read-just Aurora Replicas, this endpoint lessens the overhead on the essential occurrence. It additionally causes the group to scale the ability to deal with concurrent SELECT inquiries, corresponding to the quantity of Aurora Replicas in the bunch. Every Aurora DB bunch has one reader endpoint. The following example illustrates a reader endpoint for an Aurora MySQL DB cluster.
mydbcluster.cluster-ro-123456789012.us-east-1.rds.amazonaws.com:3306
Custom endpoint
A custom endpoint for an Aurora group speaks to a lot of DB occurrences that you pick. At the point when you interface with the endpoint, Aurora performs load adjusting and picks one of the cases in the gathering to deal with the association. You characterize which occasions this endpoint alludes to, and you choose what reason the endpoint serves. The following example illustrates a custom endpoint for a DB instance in an Aurora MySQL DB cluster.
myendpoint.cluster-custom-123456789012.us-east-1.rds.amazonaws.com:3306
Instance endpoint
An occurrence endpoint associates with a particular DB example inside an Aurora bunch. Every DB occurrence in a DB group has its own one of a kind example endpoint. So there is one example endpoint for the current essential DB occurrence of the DB bunch, and there is one case endpoint for every one of the Aurora Replicas in the DB group. The following example illustrates an instance endpoint for a DB instance in an Aurora MySQL DB cluster.
mydbinstance.123456789012.us-east-1.rds.amazonaws.com:3306
DB Instance Classes
The DB case class decides the calculation and memory limit of an Amazon RDS DB occasion. The DB example class you need relies upon your handling force and memory prerequisites.
DB Instance Class Types
Amazon Aurora bolsters two kinds of occasion classes: Memory-Optimized and Burstable Performance. For more data about Amazon EC2 occasion types, see Instance Type in the Amazon EC2 documentation.
Coming up next are the Memory Optimized DB example classes accessible:
db.r5
Latest-age example classes enhanced for memory-concentrated applications. These offer improved systems administration execution. They are controlled by the AWS Nitro System, a blend of committed equipment and lightweight hypervisor.
db.r4
Current-age occurrence classes enhanced for memory-serious applications. These offer improved systems administration execution.
db.r3
Previous-age example classes that give memory streamlining. The db.r3 cases classes are not accessible in the Europe (Paris) district.
Coming up next are the Burstable Performance DB occasion classes accessible:
db.t3
Latest-age case classes that give a benchmark execution level, with the capacity to blast to full CPU use. These occasion classes give more registering limit than the past db.t2 example classes. They are fueled by the AWS Nitro System, a mix of devoted equipment and lightweight hypervisor.
db.t2
Current-age case classes that give a pattern execution level, with the capacity to blast to full CPU use. We suggest utilizing these example classes just for advancement and test servers, or other non-production servers.
Terminology for DB Instance Class Hardware Specifications
The accompanying phrasing is utilized to depict equipment particulars for DB occasion classes:
vCPU
The quantity of virtual focal processing units (CPUs). A virtual CPU is a unit of limit that you can use to think about DB occurrence classes. Rather than buying or renting a specific processor to use for a while or years, you are leasing limit continuously. We will likely make a steady and explicit measure of CPU limit accessible, inside the restrictions of the genuine fundamental equipment.
ECU
The general proportion of the whole number preparing the intensity of an Amazon EC2 case. To make it simple for engineers to think about the CPU limit between various occurrence classes, we have characterized an Amazon EC2 Compute Unit. The measure of CPU that is assigned to a specific occurrence is communicated as far as these EC2 Compute Units. One ECU as of now gives CPU limit equal to a 1.0–1.2 GHz 2007 Opteron or 2007 Xeon processor.
Memory (GiB)
The RAM, in gibibytes, apportioned to the DB case. There is frequently a predictable proportion among memory and vCPU. For instance, take the db.r4 occurrence class, which has a memory to vCPU proportion like the db.r5 occasion class. Be that as it may, for most use cases the db.r5 occasion class gives better, more reliable execution than the db.r4 occurrence class.
Max. Transmission capacity (Mbps)
The most extreme data transfer capacity in megabits every second. Separation by 8 to get the normal throughput in megabytes every second.Note: This figure alludes to the I/O data transfer capacity for nearby capacity inside the DB occasion. It doesn't make a difference in correspondence with the Aurora group volume.
System Performance
The system speed comparative with other DB example classes.
Amazon Aurora Storage and Reliability
Diagram of Aurora Storage
Aurora information is put away in the bunch volume, which is a solitary, virtual volume that utilizes strong state drives (SSDs). A bunch volume comprises of duplicates of the information over different Availability Zones in a solitary AWS Region. Since the information is consequently imitated across Availability Zones, your information is profoundly tough with less chance of information misfortune. This replication additionally guarantees that your database is progressively accessible during a failover. It does so in light of the fact that the information duplicates as of now exist in the other Availability Zones and keep on serving information solicitations to the DB examples in your DB bunch.
What the Cluster Volume Contains
The Aurora group volume contains all your client information, composition objects, and inward metadata, for example, the framework tables and the double log. For instance, Aurora stores all the tables, files, twofold huge articles (BLOBs), put away methodology, etc for an Aurora bunch in the group volume. The Aurora shared capacity engineering makes your information free from the DB cases in the bunch.
How Aurora Storage Grows
Aurora group volumes consequently develop as the measure of information in your database increments. An Aurora group volume can develop to the most extreme size of 64 tebibytes (TiB). Table size is restricted to the size of the bunch volume. That is, the most extreme table size for a table in an Aurora DB bunch is 64 TiB. This programmed stockpiling scaling joined with the superior and profoundly appropriated capacity subsystem settles on Aurora a decent decision for your significant undertaking information when your fundamental destinations are dependability and high accessibility.
Amazon Aurora Reliability
Aurora is intended to be solid, tough, and issue open-minded. You can engineer your Aurora DB bunch to improve accessibility by doing things, for example, including Aurora Replicas and setting them in various Availability Zones, and furthermore Aurora incorporates a few programmed highlights that make it a dependable database arrangement.
Capacity Auto-Repair
Since Aurora keeps up various duplicates of your information in three Availability Zones, the possibility of losing information because of a plate disappointment is incredibly limited. Aurora naturally distinguishes disappointments in the plate volumes that make up the bunch volume. At the point when a fragment of a circle volume falls flat, Aurora quickly fixes the section. At the point when Aurora fixes the plate portion, it utilizes the information in different volumes that make up the bunch volume to guarantee that the information in the fixed fragment is current. Therefore, Aurora stays away from information misfortune and lessens the need to play out a point-in-time reestablish to recuperate from a circle disappointment.
Survivable Cache Warming
Aurora "warms" the cushion pool reserve when a database fires up after it has been closed down or restarted after a disappointment. That is, Aurora preloads the support pool with the pages for known regular inquiries that are put away in an in-memory page store. This gives a presentation gain by bypassing the requirement for the support pool to "warm up" from typical database use.
Crash Recovery
Aurora is intended to recoup from an accident immediately and keep on serving your application information without the double log. Aurora performs crash recuperation non concurrently on equal strings with the goal that your database is open and accessible following an accident.
