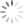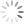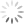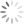


Run Word Count Java Mapreduce Program in Hadoop
In This Article, we'll discuss Run Word Count Java Mapreduce Program in Hadoop
How to create Jar file for Wordcount using eclipse IDE for Java.
1:- Create a Java project in Eclipse with name “WordCount”
2:- Create a class file named “WordCount.java” in src folder.
3:- Download hadoop-core.jar and hadoop-commons.jar.
4:-Right click on “WordCount” project -> Click on properties ->; Click on “;Java Build Path”-> Click on tab – “Libraries” -> Add External jars
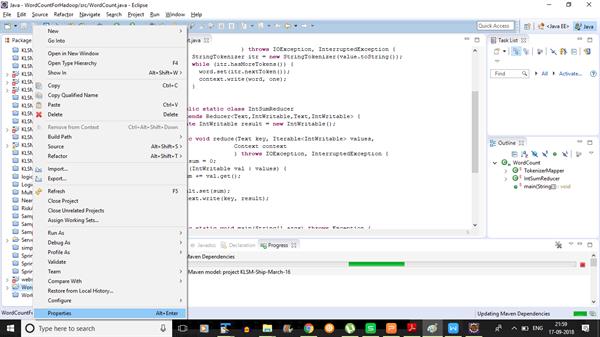
5:-Select hadoop-core.jar. Click Apply and Close
6:- Add "Mapper", "Reducer" and "Driver" code to WordCount.java
import java.io.IOException;
import java.io.InvalidObjectException;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDemo
{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum); context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration(); conf job = new conf();
//Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCountDemo.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}7:-Compile the project.
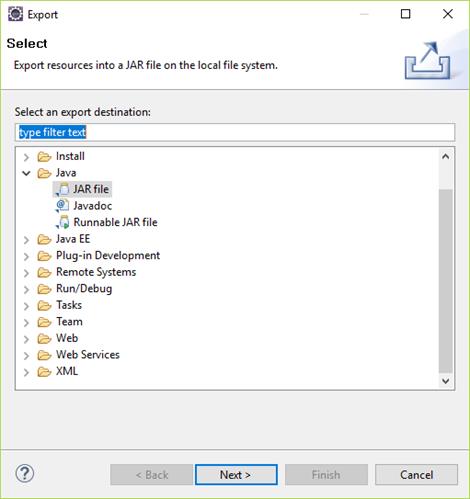
8:- Right click on project -> Export -> Jar -> Add location and name of jar.
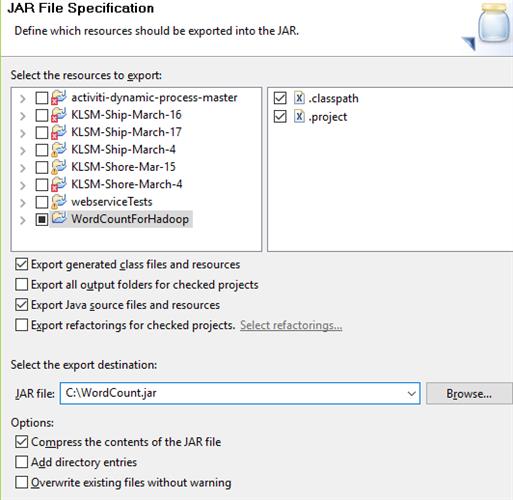
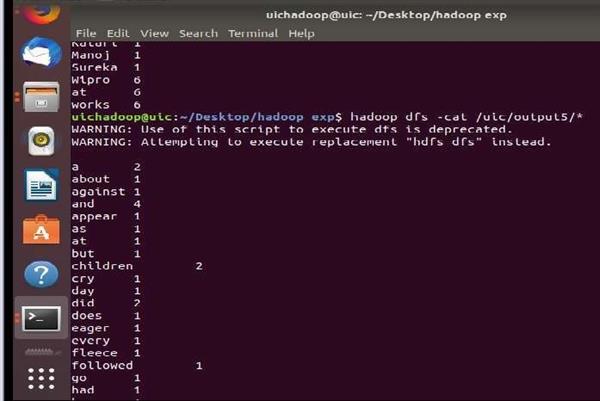
9:- when jar file will be created go to Hadoop exp copy the file and open terminal when all the services of the Hadoop get started choose the file which want to count the words
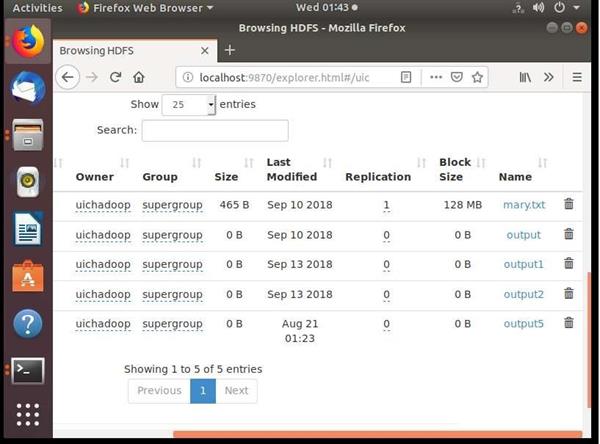
10:-show the content of the file

11:- run command to word count of the file
hadoop jar wordCount.jar wordCount
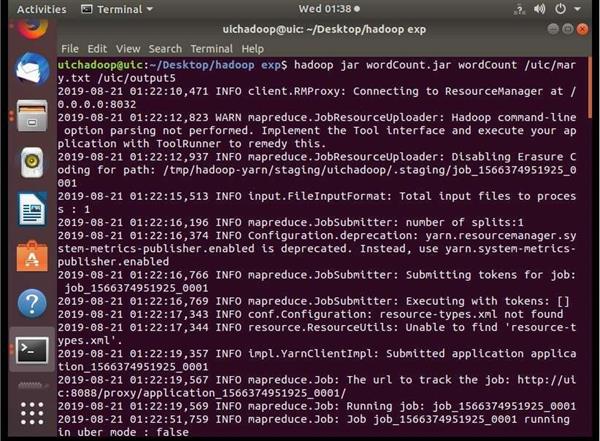
12 :- after the program get executed the output will show like this